
 in 2025")


























What is Semantic Segmentation?
Semantic segmentation is the process to allocate a semantic label to every pixel present in an image. For example, traffic sign detection aims to classify each pixel as a car, a pedestrian, or a road sign.
Semantic segmentation aims to solve classification problems with computer vision that leverages deep learning and convolutional neural networks (CNN). It involves labeling each pixel in an image with a category or class label, such as “person,” “tree,” or “car.”
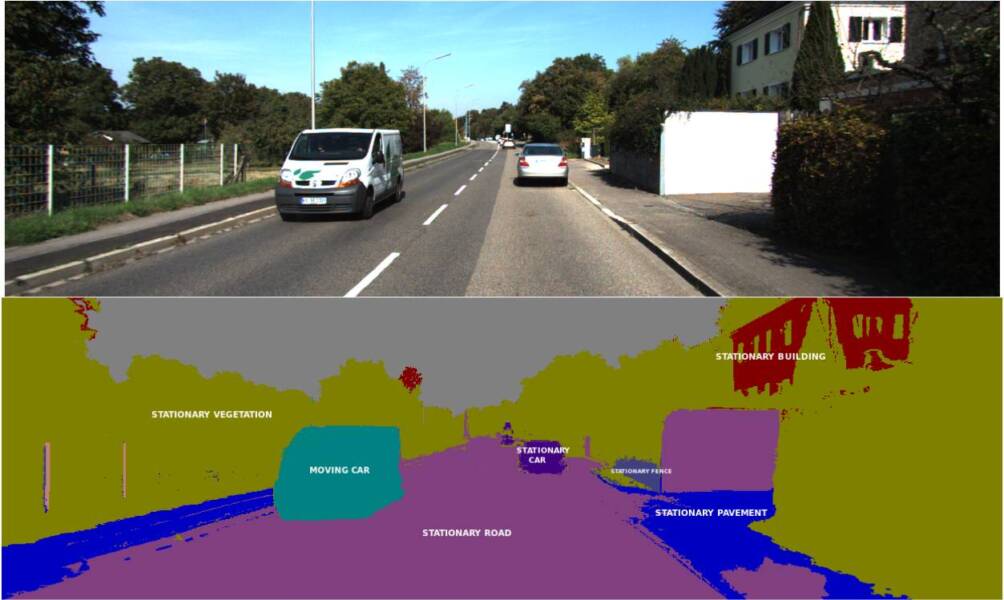
Semantic segmentation is different from standard segmentation tasks, which labels the pixels according to their physical properties (i.e., their color). It aims at annotating each pixel with its object label. The algorithm to identify objects works under the learning architecture of neural networks.
Semantic segmentation has recently gained more attention in computer vision and deep learning. This is because of its growing applications in different industries.
Different Types of Image Segmentation
Image segmentation is the process of partitioning a digital image (still images and video images) into multiple segments. These segments are homogeneous regions in terms of content and characteristics. Segmentation is used in computer vision and image processing tasks, such as object recognition and scene understanding.
Types of Image Segmentation include:
- Semantic Segmentation
- Instant Segmentation
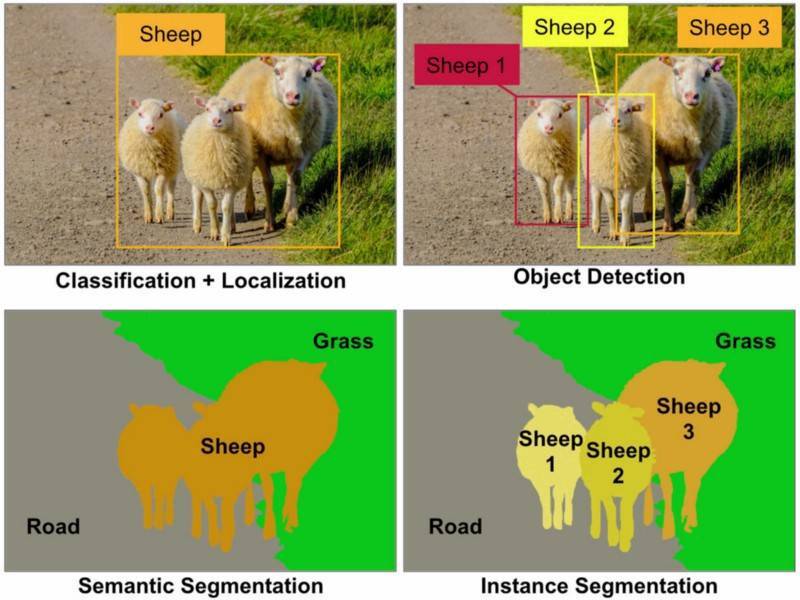
Semantic Segmentation
Semantic segmentation is a subfield of computer vision and machine learning concerned with identifying and labeling objects and other semantic elements in images. Semantic segmentation is important in tasks such as:
- Object detection
- Segmentation
- Image retrieval
- Image search
- Classification
Instance Segmentation
Instance segmentation is a computer vision problem that labels each instance in an image with its corresponding class label. This task is important for detecting individual objects in an image, which you can use for object detection and recognition tasks.
Use cases / example
Facial Recognition

Semantic segmentation is used for facial recognition. The model is trained to predict if an image contains a face or if it does not. The input image is first converted into a vector representation, which you can use for comparison against other vectors.
The idea behind this application is that you can segment a face into different regions, such as the eyes, nose, and mouth. This can then identify the person in question by comparing the image with datasets of known faces.
Here’s a breakdown of the facial recognition process:
- The verification system first analyzes the face.
- Next, the system will remove any noise and other distracting elements from the image to provide a better-quality picture.
- The system proceeds to analyze the image and determine which subject in the database the image belongs to.
- The output of this program indicates whether the subject in the input image is in the database or not.
Self-Driving Cars

Semantic segmentation is the first step toward establishing autonomous driving. To understand the world around them, cars use computer vision techniques to identify objects and their properties. The next step is to make decisions based on these observations.
For example, if a car sees a pedestrian walking on the road, it needs to know where this pedestrian is going and whether it will cross the road or not. To do that, the car needs to understand what objects are in that scene and how they will move in the future (i.e., their trajectories).
This is where semantic segmentation comes into the picture.
Medical image diagnostics
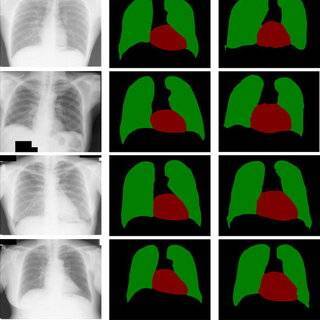
Diagnosing medical images is time-consuming, costly, and error-prone. The process involves labeling each pixel of an image with its corresponding anatomical structure. This process requires significant effort from trained experts who spend hours annotating each image.
Semantic segmentation reduces the time required for manual labeling with image annotation. The medical industry can leverage a machine-learning model that automatically labels each pixel in an image with its corresponding anatomical structure. This way, physicians can focus on actual diagnosis instead of spending time on low-value tasks such as classifying pixels in an image.
Wrapping Up
In summary, semantic segmentation is an important sector of deep learning algorithms leveraged to supercharge advancements in computer vision. Semantic segmentation will continue to advance in many of these related subcategories, object detection, classification, and localization.
 Author Bio
Author Bio
Vatsal Ghiya is a serial entrepreneur with more than 20 years of experience in healthcare AI software and services. He is the CEO and co-founder of Shaip, which enables the on-demand scaling of our platform, processes, and people for companies with the most demanding machine learning and artificial intelligence initiatives.
Linkedin: https://www.linkedin.com/in/vatsal-ghiya-4191855/
TechnologyHQ is a platform about business insights, tech, 4IR, digital transformation, AI, Blockchain, Cybersecurity, and social media for businesses.
We manage social media groups with more than 200,000 members with almost 100% engagement.


 in 2025")







